今更だけどIDLEとNumPy
Pythonを扱うのにVSCODEを使ってきた。Debugの昨日も付いているし一々コマンドプロントとエディターの間を行き来する必要もないから。
しかし、PythonにはIDLEという開発環境がPythonと一緒にインストールされる。
このIDLEでもデバッグは可能だし、IDLEから実行も可能なので暫くIDLEを使ってみることにした。
IDLEの稼働状況は
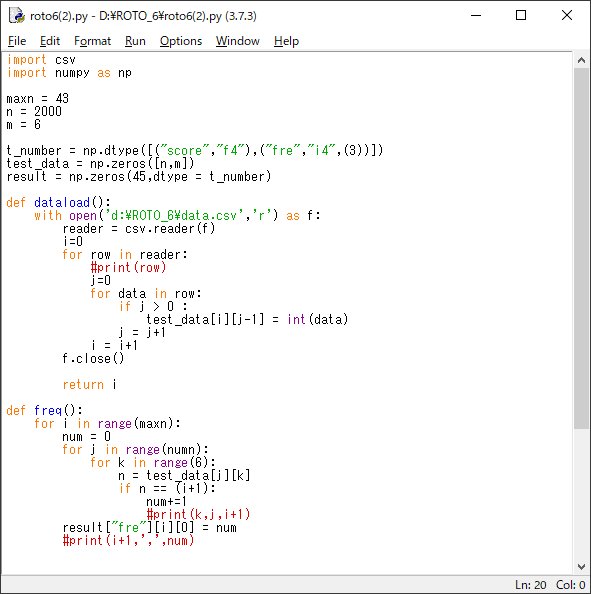
こんな感じ。
VSCODEでPythonを使う場合色々設定が必要だが、IDLEの場合は一緒にインストールされ、何も設定は必要ないので、とりつきやすいかもしれない。
なにしろ、私もPythonは使い始めで知らないことが多い。
NumPyで配列
Pythonには数多くのライブラリが存在する。というよりむしろそのライブラリがあってこそのPythonといえるのかもしれない。
前回までに使用したcsvもライブラリのひとつである。
NumPyは大規模な多次元配列や行列をサポートし、かつ高速に行列演算ができる・・・というライブラリである、らしい。
前回はPythonは数値計算には向いてないようだと書いたが、大幅に前言撤回の必要がある。
NumPyの詳しいことはググって見てほしい。
前回までは
test_data = [[0]*m for i in range(n)] result = [[0]*3 for i in range(maxn)]
のようにリストを利用して配列を構成していた。
resultには本来構造化配列を使用したいと思っていたが、それが無いので単に2次元配列で代替えしていた。
しかし、NumPyは2次元配列も構造化配列もサポートしている。
NumPyのインストール
csvは前回も使用しているライブラリだが、インストールせずに宣言することができたが、NumPyはpipを使ってインストールする必要がある。
コマンドプロンプトで >pip install numpy
でインストールできる。
pipはPythonをインストールする際に、一緒にインストールされている。
配列の再定義は
import csv
import numpy as np
maxn = 43
n = 2000
m = 6
t_number = np.dtype([("score","f4"),("fre","i4",(3))])
test_data = np.zeros([n,m])
result = np.zeros(45,dtype = t_number)
t_number = np.dtype([(“score”,”f4″),(“fre”,”i4″,(3))])
は、構造体の定義、ということになるか。
score:後で評価値(浮動少数)、fre:出現回数3個の配列(整数)
の型の宣言
test_data = np.zeros([n,m])は、test_dataに2000×6の配列の確保。
result = np.zeros(45,dtype = t_number)は、t_numberの型で45個の配列を確保する。
リストを使った配列よりも少し考え方が複雑だが、後で計算や出力するときには逆に楽になる。
データの読み込み、出現回数の計算を含めたソースは
import csv
import numpy as np
maxn = 43
n = 2000
m = 6
t_number = np.dtype([("score","f4"),("fre","i4",(3))])
test_data = np.zeros([n,m])
result = np.zeros(45,dtype = t_number)
def dataload():
with open('d:\ROTO_6\data.csv','r') as f:
reader = csv.reader(f)
i=0
for row in reader:
#print(row)
j=0
for data in row:
if j > 0 :
test_data[i][j-1] = int(data)
j = j+1
i = i+1
f.close()
return i
def freq():
for i in range(maxn):
num = 0
for j in range(numn):
for k in range(6):
n = test_data[j][k]
if n == (i+1):
num+=1
#print(k,j,i+1)
result["fre"][i][0] = num
numn = dataload()
for i in range(numn):
v1 = test_data[i]
print(i+1,v1)
freq()
for i in range(maxn):
print(result["score"][i],result["fre"][i])
この中で、result[“fre”][i][0] = numは、resultの配列のi番目のデータのfre型の配列の0番目のデータを意味する。
普通の(C,C#,Delphi)言語をやっていると逆に分かりにくい(思うのだが)
そして、その結果は
====== RESTART: D:\ROTO_6\roto6(2).py ===
1 [ 2. 8. 10. 13. 27. 30.]
2 [ 1. 9. 16. 20. 21. 43.]
3 [ 1. 5. 15. 31. 36. 38.]
4 [16. 18. 26. 27. 34. 40.]
5 [ 9. 15. 21. 23. 27. 28.]
6 [ 6. 12. 23. 25. 28. 38.]
.
.
.
1380 [ 1. 3. 24. 26. 29. 33.]
1381 [ 2. 4. 5. 16. 19. 38.]
1382 [ 8. 9. 12. 25. 26. 28.]
1383 [ 2. 4. 9. 15. 18. 39.]
1384 [ 3. 6. 13. 32. 38. 43.] ここまでデータの確認
1 0.0 [185 0 0]
2 0.0 [198 0 0]
3 0.0 [197 0 0]
4 0.0 [192 0 0]
5 0.0 [192 0 0]
.
.
.
40 0.0 [179 0 0]
41 0.0 [177 0 0]
42 0.0 [190 0 0]
43 0.0 [198 0 0] score,[fre[0],fre[1],fre[2]]
開発環境も含めかなり後戻りになったが、これから後の作業が進めやすくなった。
と、いうことで
再スタート